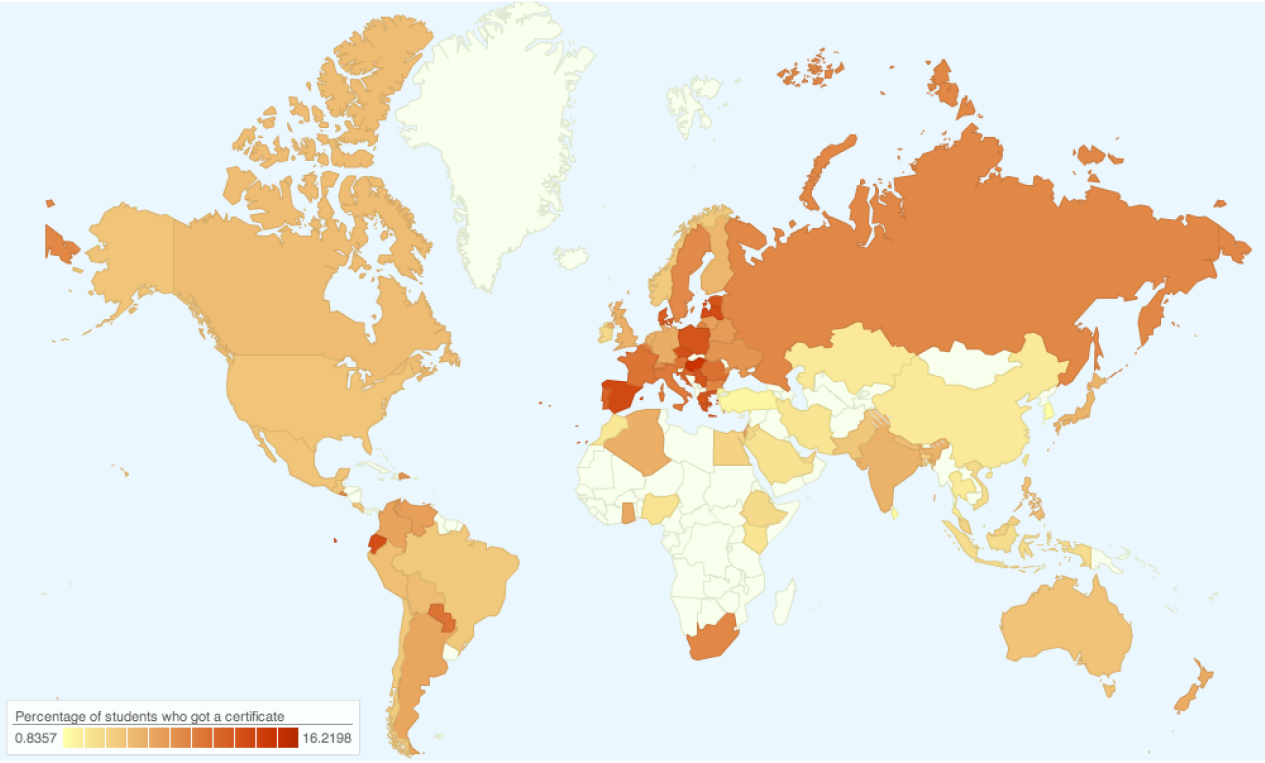
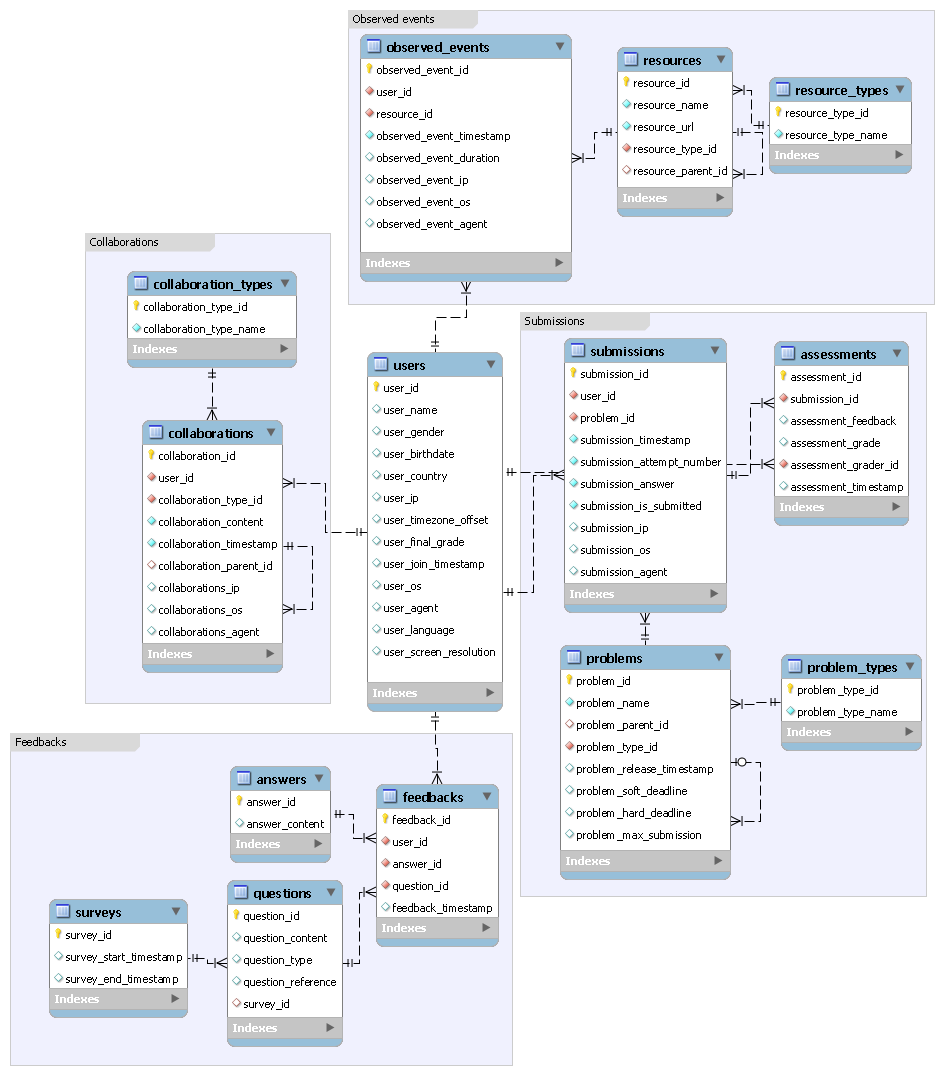
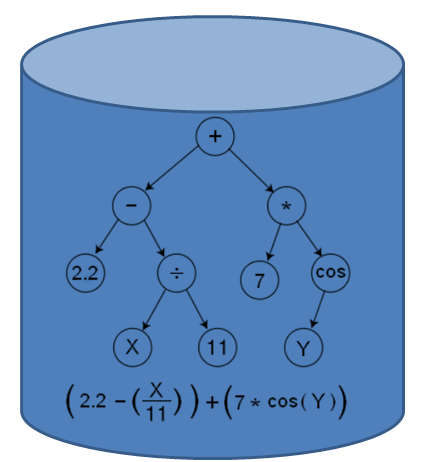
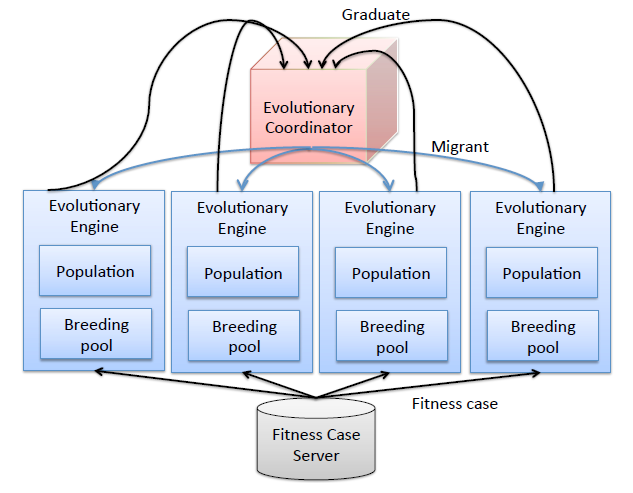
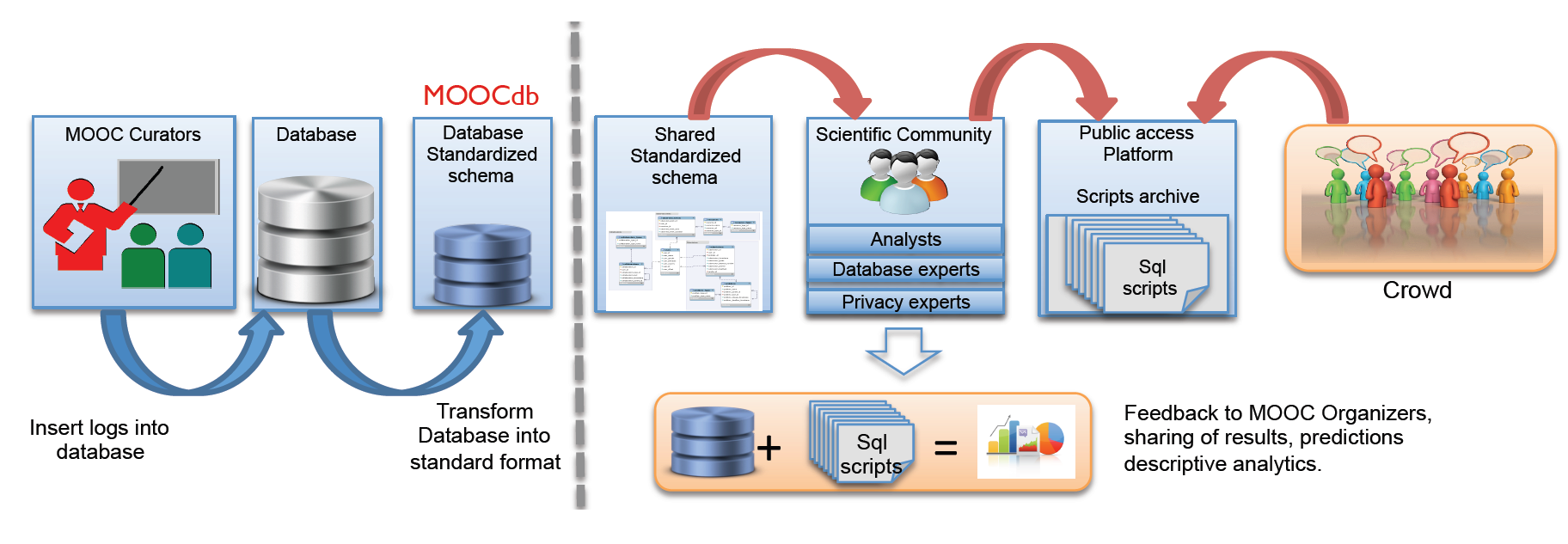
Kalyan Veeramachaneni, Franck Dernoncourt, Colin Taylor, Zachary A. Pardos, Una-May O'Reilly. "MOOCdb: Developing Data Standards for MOOC Data Science." MOOCShop at Artificial Intelligence in Education, 2013.
Abstract: The intent of this article is to propose data standards for MOOCs. Our team has been conducting research related to mining information, building
models, and interpreting data from the inaugural course offered by edX, 6.002x:
Circuits and Electronics, since the Fall of 2012. This involves a set of steps,
undertaken in most data science studies, which entails positing a hypothesis,
assembling data and features (aka properties, covariates, explanatory variables,
decision variables), identifying response variables, building a statistical model
then validating, inspecting and interpreting the model. In our domain, and others
like it that require behavioral analyses of an online setting, a great majority of
the effort (in our case approximately 70%) is spent assembling the data and
formulating the features, while, rather ironically, the model building exercise
takes relatively less time. As we advance to analyzing cross-course data, it has
become apparent that our algorithms which deal with data assembly and feature
engineering lack cross-course generality. This is not a fault of our software design.
The lack of generality reflects the diverse ad hoc data schemas we have adopted
for each course. These schemas partially result because some of the courses are
being offered for the first time and it is the first time behavioral data has been
collected. As well, they arise from initial investigations taking a local perspective
on each course rather than a global one extending across multiple courses.



|
|